Modern businesses leverage many IT systems to provide the capabilities to enable operational processes and users to be effective. In order for complex IT environments to run smoothly, businesses are placing increased focus on how systems are integrated and the activities required to manage integrations across the ecosystem.
While system integration is a multi-layered challenge, the essential part to get right is your enterprise data integration strategy.
Precise planning and excellent execution will take time, but it is worth it. Here’s why:
1. Quick and simple connections
Before automated integration software, manually connecting systems was a scrupulous routine involving complex programming. The traditional point-to-point connection method requires manual coding that interconnects each subsystem separately. This method quickly became difficult to maintain once more than two connections were introduced.
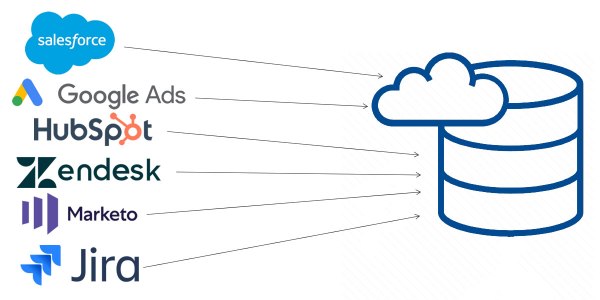
Fortunately, modern cloud data integration solutions are programmed with pre-built connectors that easily connect established systems, allowing smooth data sharing. The advanced architecture of these tools limits the integration setup time and enables developers to work on one end of the system without affecting the other. Etlworks data integration platform has 220+ highly configurable read/write connectors for almost all relational and NoSQL databases, cloud data warehouses, local and cloud-based file storage services, data exchange formats, APIs, business applications, and SaaS data sources.
2. Data barrier removal
Different industries call for different systems that cater to the business’s specific needs. For example, a retailer may require customer relationship management and marketing software, whereas a restaurant may need a menu and perishable food management solution.
This wide range of services often results in information silos that categorize data based on the operation. However, these silos can limit communication throughout a company by denying access to insights on operations outside of a specific department.
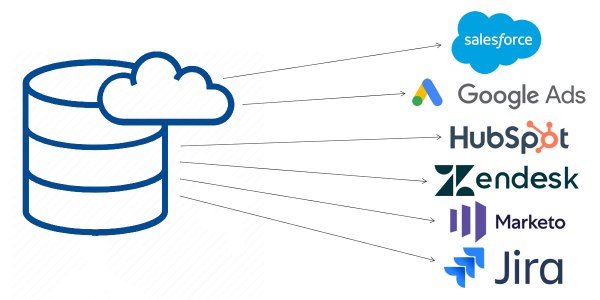
Data integration software breaks down these barriers to allow data exchange between departments. Advanced solutions also enable businesses to connect with external parties such as suppliers, manufacturers, and distributors to streamline outside operations.
3. Easy access to data
Available data is an advantage for your business; it’s as simple as that! Imagine that anyone in your company, or even your business partners, could have access to centralized information. Centralizing your data makes it easy for anyone at your company (or outside of your company, depending on your goals) to retrieve, inspect, and analyze it.
Easily accessible data means easily transformed data. People will be more likely to integrate the data into their projects, share the results, and keep the data up to date. This cycle of available data is key for innovation, knowledge-sharing, and continuing to develop your data integration plan.
4. Smart decision-making
A human decision is always based on information, personal experience, emotion, and knowledge. The more information is available, the more likely it is to have a favorable outcome. Backing this with data also allows a unified view of all strategic or business process decisions as well as higher transparency. The smarter your decisions are, the smarter your enterprise will be.
5. Easy data collaboration
With accessibility comes easier collaboration. When a data integration plan is in place, anyone who works with your data will find it easier to use brain power now. They can actually use the data in the format they require. Whether collaboration involves sharing among internal teams and applications, or across organizations, integrated data is more complete because it has more contributors.
6. Increased data accuracy
Data that is inaccurate or outdated cannot be used to generate insights or make business decisions. Therefore, companies must have access to quality information.
Modern integration software ensures data is always up to date and accurate by continuously collaborating information whenever an event occurs, or new data is entered. Through automation, software solutions do not require human intervention, limiting exposure to security issues and human error.
7. Gain a competitive advantage
Perhaps the most significant benefit of data integration is the ability to derive actionable insights that give businesses an edge over their competitors. By connecting and consolidating data, leaders gain visibility into the organization’s performance, increase speed and agility in decision making, and improve accuracy.
Data is getting larger, faster, and more diverse. This influx of knowledge can make businesses more accurate, more nimble, and ultimately more successful — but only if they have the data architecture in place to make it a functional part of their decision-making. Integration, when done well, empowers leaders and their staff to leverage the massive amounts of data all modern organizations collect. It is a mechanism for making this wealth of information more usable.
The Bottom Line: Make Integration a Priority
Developing an integration strategy—both the technical and business aspects—is critical to assuring your organization’s data reaches its maximum potential. Learn more about data integration and how Etlworks can help your organization develop a data integration plan – no matter how big or small your data is, spatial or tabular, structured or unstructured, open or proprietary, or all the above.