
To gain business insights for competitive advantage every business these days is seeking ways to integrate data from multiple sources. Data and data analytics are critical to business operations, so it’s important to engineer and deploy strong and maintainable data pipelines.
A data pipeline is a set of actions that ingest raw data from disparate sources and move the data to a destination for storage and analysis. Most of the time, though, a data pipeline is also to perform some sort of processing or transformation on the data to enhance it.
Data pipelines often deliver mission-critical data and for important business decisions, so ensuring their accuracy and performance is required whether you implement them through data integration and ETL platforms, data-prep technologies, or real time data streaming architectures.
How is a data pipeline different from ETL?
You may commonly hear the terms ETL and data pipeline used interchangeably. ETL stands for Extract, Transform, and Load. The major dissimilarity of ETL is that it focuses entirely on one system to extract, transform, and load data to a particular data warehouse. Alternatively, ETL is just one of the components that fall under the data pipeline.
ETL pipelines move the data in batches to a specified system with regulated intervals. Comparatively, data pipelines have broader applicability to transform and process data through streaming or real-time.
Data pipelines do not necessarily have to load data to a database or data warehouse. It might be loaded to any number of targets, such as an AWS bucket or a data lake, or it might even trigger a webhook on another system to kick off a specific business process.
Data pipeline solutions
The nature and functional response of data pipeline would be different from cloud tools to migrate data to outright use it for a real-time solution. The following list shows the most popular types of pipelines available. Note that these systems are not mutually exclusive. For example, you might have a data pipeline that is optimized for both cloud and real-time.
Cloud-Based
The cost-benefit ratio of using cloud-based tools to integrate data is quite high. These tools are hosted in the cloud, allowing you to save money on infrastructure and expert resources because you can rely on the infrastructure and expertise of the vendor hosting your pipeline.
Batch
Batch processing allows you to easily transport a large amount of data at interval without having to necessitate real-time visibility. The process makes it easier for analysts who combine a multitude of marketing data to form a decisive result or pattern.
Real-Time or Streaming
Real-time or streaming processing is useful when an organization processes data from a streaming source, such as the data from financial markets or internet of things (IoT) devices and sensors. Real-time processing captures data as it comes off the source systems in real time, performs rudimentary data transformations (filters, samples, aggregates, calculates averages, determines min/max values) before firing off data to the downstream process.
Open Source
Open Source tools are ideal for small business owners who want lower cost and over-reliance on commercial vendors. However, the usefulness of such tools requires expertise to use the functionality because the underlying technology is publicly available and meant to be modified or extended by users.
Data pipeline use cases
Data Migration
Data pipelines are used to perform data migration tasks. These might involve moving data from databases, e.g. MongoDB, Oracle, Microsoft SQL Server, PostgreSQL, and MySQL into the cloud. Cloud databases are scalable and flexible and enable for easier creation of other data pipelines that use real-time streaming.
Data Warehousing and Analysis
Probably the most common destination for a data pipeline is a dashboard or suite of analytical tools. Raw data that is structured via ETL can be loaded into databases for analysis and visualization. Data scientists can then create graphs, tables and other visualizations from the data. This data can then be used to inform strategies and guide the purpose of future data projects.
AI and Machine Learning Algorithms
ETL and ELT pipelines can move data into machine learning and AI models. Machine learning algorithms can learn from the data, performing advanced parsing and wrangling techniques. These ML models can then be deployed into various software. Machine learning algorithms fed by data pipelines can be used in marketing, finance, science, telecoms, etc.
IoT Integration
Data pipelines are frequently used in IoT systems that use networks of sensors for data collection. Data inducted from various sources across a network can be transformed into data available for ready analysis. For example, an ETL pipeline may perform numerous calculations on huge quantities of delivery tracking information, vehicle locations, delay expectations, etc, to form a rough ETA estimate.
Getting started with a data pipeline
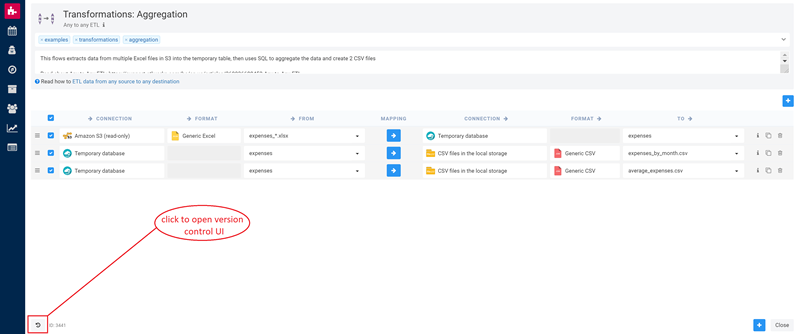
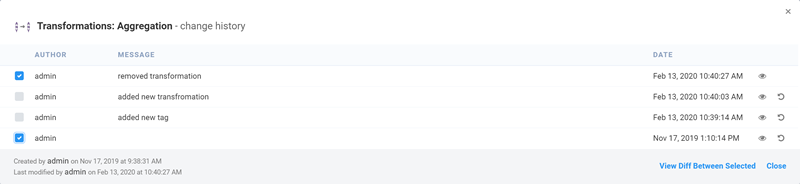
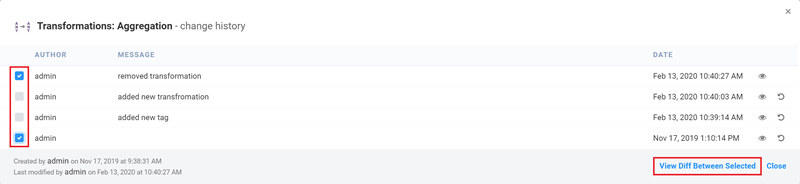
Setting up a reliable data pipeline doesn’t have to be complex and time-consuming. Etlworks can help you solve your biggest data collection, extraction, transformation, and transportation challenges. Sign up for Etlwoks for free and get the most from your data pipeline, faster than ever before.







{kind=link}